|
转自:http://hi.baidu.com/yaomohan/blog/item/e7b1c2c2516638110ef477cc.html 经过N天的努力,我的第一个文本聚类小程序终于火热出炉了.真不容易啊,在网上看了很多程序才明白其中的核心原理。其实原理很简单,但这个程序最麻烦的是 一些细节,比如字符串的处理还有用什么样的数据结构来存储数据等等,这些才是最麻烦的。下面我会详细介绍我所总结的东西,由于是我自己总结的所以难免会有 一些错误,望广大网友,牛人指出错误,谢谢合作!!! 首先我来介绍一下什么是文本聚类,最简单的来说文本聚类就是从很多文档中把一些 内容相似的文档聚为一类。文本聚类主要是依据著名的聚类假设:同类的文本相似度较大,而不同类的文本相似度较小。作为一种无监督的机器学习方法,聚 类由于不需要训练过程,以及不需要预先对文本手工标注类别,因此具有一定的灵活性和较高的自动化处理能力,已经成为对文本信息进行有效地组织、摘要和导航 的重要手段,为越来越多的研究人员所关注。一个文本表现为一个由文字和标点符号组成的字符串,由字或字符组成词,由词组成短语,进而形成句、段、节、章、 篇的结构。要使计算机能够高效地处理真是文本,就必须找到一种理想的形式化表示方法,这种表示一方面要能够真实地反应文档的内容(主题、领域或结构等), 另一方面,要有对不同文档的区分能力。目前文本表示通常采用向量空间模型(vector space model,VSM)。 VSM法即向量空间模型(Vector Space Model)法,由Salton等人于60年代末提出。这是最早也是最出名的信息检索方面的数学模型。其基本思想是将文档表示为加权的特征向 量:D=D(T1,W1;T2,W2;…;Tn,Wn),然后通过计算文本相似度的方法来确定待分样本的类别。当文本被表示为空间向量模型的时候,文本的 相似度就可以借助特征向量之间的内积来表示。最简单来说一个文档可以看成是由若干个单词组成的,每个单词转化成权值以后, 每个权值可以看成向量中的一个分量,那么一个文档可以看成是n维空间中的一个向量,这就是向量空间模型的由来。单词对应的权值可以通过TF-IDF加权技 术计算出来。 TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的 其中一份文件的重要程 度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式 常被搜索引擎应用,作为文件与用户查询之间相关程度 的度量或评级。除了TF-IDF以外,互联网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。 原理: 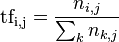 以上式子中ni,j是该词在文件dj中的出现次 数,而分母则是在文件dj中所 有字词的出现次数之和。 逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:  其中
然后  某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词 语,保留重要的词语。 例子有很多不同的数学公式可以用来计 算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是 0.03 (3/100)。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是 10,000,000份的话,其逆向文件频率就是 9.21 ( ln(10,000,000 / 1,000) )。最后的TF-IDF的分数为0.28( 0.03 * 9.21)。TF-IDF权重计算方法经常会和余 弦相似度(cosine similarity)一同使用于向 量空间模型中,用以判断两份文件之间的相 似性。学过向量代数的人都知道,向量实际上是多维空间中有方向的线段。如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。而要确定两 个向量方向是否一致,这就要用到余弦定理计算向量的夹角了。 最后我们在对文本进行聚类时要用到数据挖掘中的Kmeans算法,聚类算法有很多种,这篇文章主要介绍Kmeans算法。K-MEANS算法: k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对 象”(引力中心)来进行计算的。 处理流程: (1)从c个 数据对象任意选择k个 对象作为初始聚类中心; 到这里这个文本聚类的小程序的核心思想就讲完了,总的来说大致步骤如 下: (1)对各个文本分词,去除停用词 (2)通过TF-IDF方法获得文本向量的权值(每个文本向量的维数是 相同的,是所有文本单词的数目,这些单词如果有重复那只算一次,所以如果文本越多,向量的维数将会越大) (3)通过K-means算法对文本进行分类 本人的文本小程序的结 果还算令人满意,对下面的实验用例的聚类结果还算是理想,但是每次执行的结果都不一样。其实聚类的结果受好多种因素制约,提取特征的算法,随机初始化函 数,kmeans算法的实现等,都有优化的地方,不信你把输入的数据的顺序改改,聚类结果就不一样了,或者把随机数的种子变一下,结果也不一样,k- means算法加入一些变异系数的调整,结果也不一样,提取特征的地方不用TF/IDF权重算法用别的,结果肯定也不一样。 实验用例: 奥运拳击入场券基本分罄邹市明夺冠对手浮出水面 以下是我在网上参考的资料: http://www.cnblogs.com/onlytiancai/archive/2008/05/10/1191557.html http://hi.baidu.com/zhumzhu/blog/item/fc49ef3d19b0a4c09f3d62a3.html |
vergilwang
- 浏览: 124816 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (341)
- Java (18)
- J2EE (0)
- Linux (81)
- VIM (22)
- windows (6)
- DB (11)
- Algorithm (57)
- Data structure (17)
- JS (5)
- C++ (65)
- HTML (6)
- Cloud (4)
- Eclipse (7)
- Python (42)
- Play (3)
- HTTP (1)
- awk (7)
- shell (20)
- Regular expression (5)
- NLP (33)
- ML (38)
- DM (43)
- Probabilistic (6)
- Crawler (14)
- matlab (1)
- perl (4)
- Design pattern (1)
- IO[File] (2)
- Deep Learning (1)
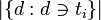 : 包含词语
: 包含词语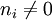 的 文件数目)
的 文件数目)



分享到:


发表评论

-
DeepLearning索引
2017-03-06 16:14 26750课:http://www.cnblogs.com/to ... -
人工智能——归结演绎推理
2011-10-26 09:46 405人工智能——归结演绎推理 1.子句 1)文字:原子谓 ... -
决策树ID3算法
2012-01-25 21:07 265http://leon-a.javaeye.com/blog ... -
Karush-Kuhn-Tucker 最优化条件 (KKT 条件)(转载)
2012-02-04 23:37 732一般地,一个最优化数学模型能够表示成下列标准形式: ... -
拉格朗日 SVM KKT
2012-02-04 23:39 358在R中使用支持向量机(SVM)(1) 1. 线性S ... -
SVM中的Karush-Kuhn-Tucker条件和对偶问题
2012-02-04 23:47 381因为这里公式编辑不方便,为求严谨,写在word上截图,图片边 ... -
求置信区间
2012-02-20 11:17 530英文为:binomial proportion confid ... -
学习SVM
2012-03-14 22:10 590【转载请注明出处】http://www.cnblogs ... -
EM算法
2012-03-14 22:11 384(EM算法)The EM Algorithm EM ... -
Latent dirichlet allocation note -- Prepare
2012-03-21 10:29 340转自莘莘学子blog :http ... -
LDA
2012-03-27 10:44 378关键所在:it posits that each docum ... -
Simple Introduction to Dirichlet Process
2012-03-27 10:50 350http://hi.baidu.com/zcfeiyu123/ ... -
关于Latent Dirichlet Allocation及Hierarchical LDA模型的必读文章和相关代码
2012-03-27 11:07 483LDA和HLDA:(1)D. M. Blei, et al., ... -
Latent dirichlet allocation note
2012-03-29 18:55 3762 Latent Dirichlet Allocat ... -
Latent semantic analysis note(LSA)
2012-03-29 18:58 4161 LSA Introduction LSA(la ... -
SVD奇异值分解
2012-03-29 18:59 316SVD分解 SVD分解是LSA的数学基础,本文是我的LS ... -
伽马贝塔函数
2012-03-31 12:34 627在数理方程、概率论等学科经常遇到以下的含参变量的积分 , ... -
狄拉克δ函数(Dirac Delta function)
2012-04-19 14:07 1254PS:狄拉克δ函数(Dirac Delta function ... -
Beli Makfile for linux
2012-04-25 13:12 322.SUFFIXES: .c .u CC= gcc # CFLA ... -
Entropy
2012-05-18 09:43 347相对熵(relative entropy)又称为KL散度(K ...
相关推荐
设计并实现了一个并行K-means聚类算法和Web文本聚类原型系统,可进行并行K-means算法的划分聚类和基于层次的组平均聚类。利用几 组Web文本数据集对基本的K-means算法和改进的算法以及基于层次的组平均算法进行试验和...
文本聚类 文本聚类的一种实现,使用 k-means 进行聚类,并使用作为距离度量。 等等,什么? 基本上,如果您有一堆文本文档,并且您想按相似性将它们分成 n 个组,那么您很幸运。 例子 为了测试这一点,我们可以查看...
文本聚类是在没有学习的条件下对文本集合进行组织或划分的过程,基本思想是要将相似的文本 划分到同一个类中. 文本聚类技术能够用来发现大规模文本集合的分类体系,以及为文本集合提供一个 概括视图;它在信息自动获取,...
灰度动态范围压缩是一种基本的图像增强处理方法,广泛应用于图像识别,视频监控等领域中。结合这一应用,提出了一种基于非线性变换的动态范围压缩算法,并且以FPGA为基础,针对一幅图像的处理进行硬件实现,给出了...
针对模糊文本聚类算法(FCM)对输入顺序以及初始点敏感的问题,提出了一种使用蚁群优化的模糊聚类算法(FACA)。该算法采用蚁群聚类算法(ACA)找到聚类的初始中心点,以解决模糊聚类的输入顺序以及初始点敏感等问题...
2)文本聚类取实验使用任意方法或 NLP 工具,编写文本聚类程序。 要求: 1 需要 2 个测试集的重复实验。 2 每个测试集文档数目大于 30 个,明确类别大于 2 个. 3 计算聚类准确度。 4. 实验要求 1)提交实验报告,给...
针对训练文本集中往往存在多个主题类别的问题,提出一种基于聚类分析策略的文本偏好挖掘方法。其基本思路是对训练文档集进行聚类处理,然后对同主题文档进行共性分析,并经过特征权值调整和特征约简,获得表示用户...
实验五 K-Means聚类算法.ipynb
。。。
。。。
摘要文本挖掘(TextMining)是一个从非结构化文本信息中获取用户感兴趣或者有用的模式的过程。其中简历数据是一类内容以个人基本信息为主,语言精短、简约、明快
从基本概念出发,逐步介绍中文分词,词性标注,命名实体识别,信息删除,文本聚类,文本分类,句法分析这几个热门问题的算法原理与工程实现。本项目初步帮助更多同路人能够快速的掌握NLP的专业知识,理清知识要点,...
本文通过利用微博热点话题舆情数据,结合聚类分析的方法,带领读者深入了解聚类分析的原理和应用。在分析过程中,将提取聚类分析中的核心逻辑,简化代码实现过程,保留关键功能,包括数据预处理、特征提取、聚类算法...
文本分类一般包括了文本的表达、 分类器的选择与训练、 分类结果的评价与反馈等过程,其中文本的表达又可细分为文本预处理、索引和统计、特征抽取等步骤。文本分类系统的总体功能模块为: (1) 预处理:将原始语料...
NLP基本任务NLP基础演示:文本分类聚类,情感分析,文本匹配,问答系统任务1:文本分类新闻标题分类
词语语义相似度计算在信息检索、文本聚类、语义消歧等方面有着广泛的应用。针对知网中现有词语语义相似度计算方法未考虑义原距离与义原深度的主次关系进行了研究,通过约束义原深度因素来改进义原相似度算法;另外,...
textClusteringDBSCAN:使用基于密度的空间聚类(DBSCAN)使用TF-IDF,FastText,GloVe字向量对文本进行聚类 这是一个库,用于根据数据中的文本字段执行不受监督的语言功能。 API也将发布以进行实时推理。 这只是...
DBSCAN_Modified_py39.py——修改后的代码,增加了将结果输出到文本的功能,仅测试了Python 3.9.5 基本用法: 1、安装Python 只使用原始代码,请安装3.7(及以下)的Python 3,如果要使用修改后的代码,建议安装3.9...